Explores the data set of roughly 25,000 records for males between the age of 18 and 70 who are full time workers to study if African males had wage differences than other two races.
This report explores the data set of roughly 25,000 records for males between the age of 18
and 70 who are full time workers and intend to answer the following two research questions
with the final linear regression model that incorporates all relevant variables, interactions and
functional forms of the covariates. The research questions are shown in the following
paragraph:
Do African American males have statistically different wages compared to Caucasian
males?
Do African American males have statistically different wages compared to all other
males?
First, plot the scatter plots of different explanatory variables versus the explained variable,
which is the logarithm of wage. The scatter plot of commuting distances versus log(wage)
seems reasonable, forming a rectangular shape centering on a horizontal line.
Fig 1
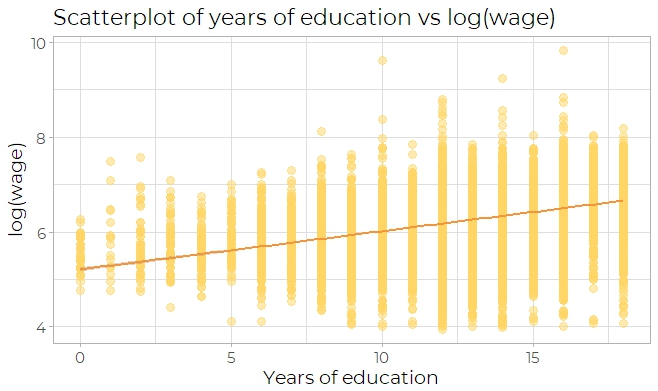
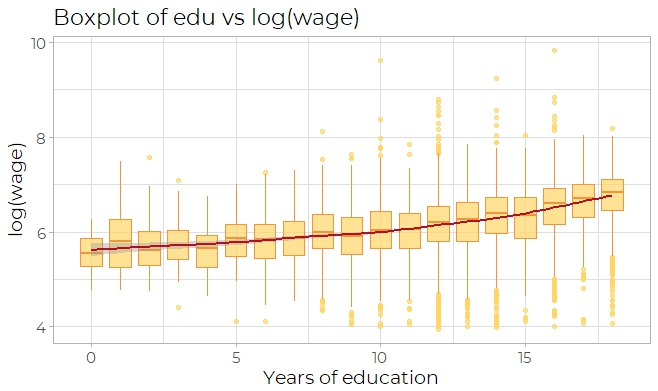
Then trying the scatter plot of years of education versus logarithm of wage, which has an
increasing trend as years of education get larger (Fig 2a). This trend can be inspected
more clearly by observing a box plot of education versus logarithm of wage(Fig 2b).
Fig 2a Fig 2b
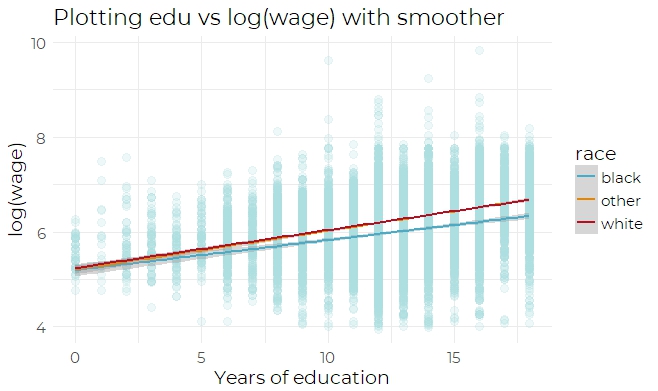
Next, it is suspected that race might have interactions with other explanatory variables.
For example, we can try inspecting the interaction between race and education. By
plotting the scatter plot of edu versus log(wage) and using the smoother(Fig 3a), we can
observe that the African Americans get a lower wage compared to Caucasians and others.
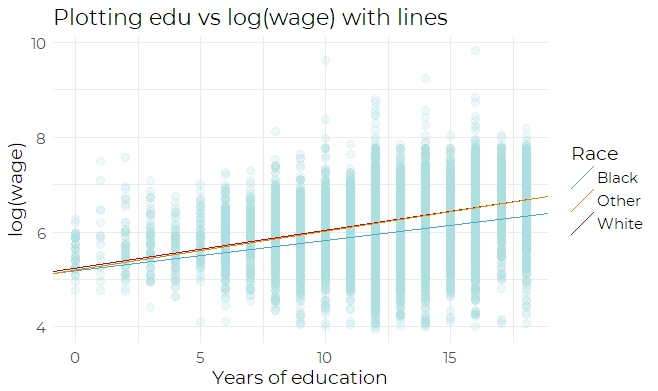
The same conclusion can be arrived by inspecting Fig 3b, the scatter plot of edu versus
log(wage) using lines. Therefore, an interaction effect between education and race(the
product of exp and race) is added to the refined model. After adding the interaction effect,
run a R summary to check if the interaction is significant. Here is the interaction statistic
taken from the summary output:
It can be concluded that the interaction terms are not significant (p-values very large,
bigger than 0.05). Therefore, it is safe to continue with this model.
Fig 3a Fig 3b
In the above analysis, only the commuting distance and education scatterplots are checked,
which is not enough for inspecting the model. Therefore, we plot the scatterplot relates to
years of job experience (Fig 4) and the one for number of employees in a company (Fig 5).
By inspecting the scatterplot of exp, it is obvious that it follows a curvilinear shape.
Therefore, some adjustments should be made to the exp variable (i.e. adding a polynomial
form of exp). The scatterplot of emp looks similar to the scatterplot of commuting
distance. Therefore, no adjustment is needed for emp variable.
Fig 4 Fig 5
Statistical Model
The final model follows the following formula:
$$log(wage) = edu + edu*race + exp + exp^2 + exp^3 + city + reg + race + deg + emp$$
The model included an interaction between edu and race, a logarithm transformation of
wage and a polynomial form of exp (exp, exp^2 and exp^3).
The R^2 is 0.3486. The adjusted R^2 is 0.3482. The AIC is 29843.85.
Research Question
Question 1
Step 1) State null hypothesis and alternative hypothesis
H0: race black=race white
HA: race black ≠ race white
Step 2) Check the value of p-value
Look at the summary output, the p-value of racewhite is 0.002140, which is lower than
0.05. Therefore, we reject the null hypothesis that the African American males have the
same wages as Caucasian males. So African American males have statistically different
wages compared to Caucasian males.
Question 2
Step 1) State the null hypothesis and alternative hypothesis
H0: race black = race white = race other
HA: race black ≠ at least one race
The p-value of race is less than 2.2e-16, which is much lower than 0.05. Therefore, we
reject the null hypothesis that African American males have the same wages as all other
males. So African American males have statistically different wages compared to all other
males.
Appendix
a. Model Selection
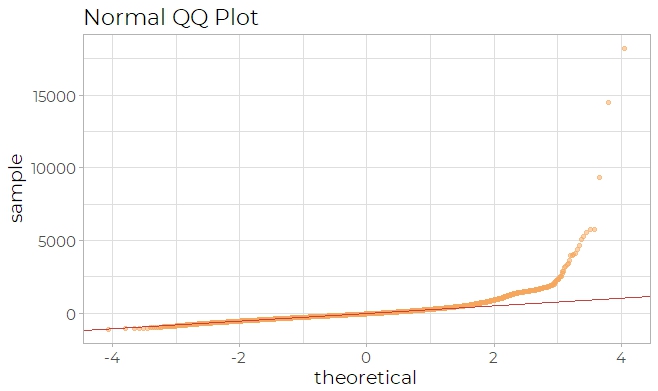
In this model, a logarithm transformation is applied to the response variable (wage). By
inspecting the qq plot (Fig 6a), it is clear that the right tail of the shape departs from
linearity, which suggests that the error distribution is not normal. Therefore, a logarithm
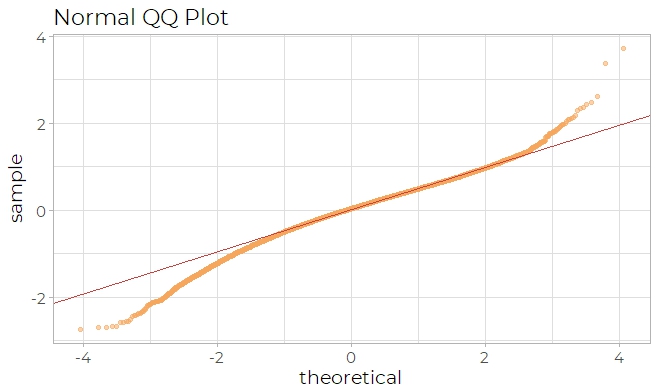
transformation of wage should be performed. After adjusting the model, the qq plot (Fig
6b) seems more linear than before.
Fig 6aFig 6b
An interaction between edu and race is used in model. This is because the scatter plot
(Fig 3a and Fig 3b) shows a relationship between edu and race: as years of education
increases, log(wage) also increases; however, black people keep having a wage lower than
other races. Therefore, this interaction is included.
After adding the interaction term, a best subset algorithm is used based on AIC. The
output is showed in the following paragraph:
This output suggests that we should drop the com variable. After dropping the
unnecessary variable, we go back to the EDA process and plot the scatter plots of exp
versus log(wage) (Fig 4) and emp versus log(wage) (Fig 5), which by inspecting those
plots, it can be recognized that the exp variable exhibits a curvilinear form, and therefore
can be expressed in a polynomial functional form. We first tried to add exp^2, but resulted
in significant interaction term: edu:racewhite with p-value of 0.033508. Therefore, exp^3 is
tried and resulted in insignificant interaction terms.
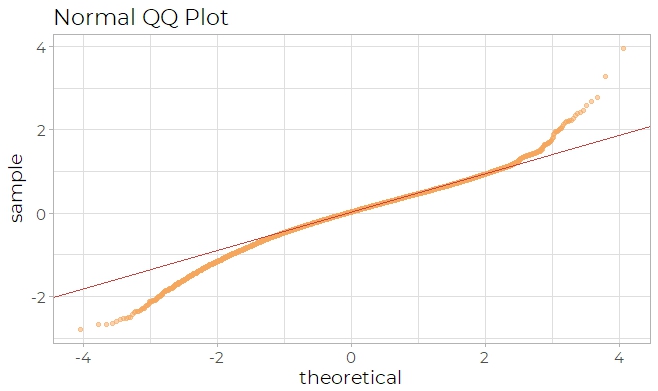
There are four kinds of plots used in this diagnostic process: qq plot, residual plot, box
plot and line plot. The first one used is the qq plot (Fig 7), which looks like the qq plot
after the log transformation and the linearity is acceptable.
Fig 7
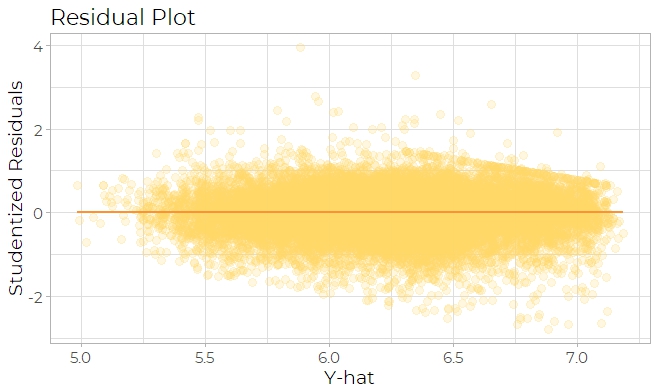
The second kind of diagnostic plot used is residual plot, which can be categorized into two
section: one is fitted y value versus Studentized residuals, and the other is explanatory
variable versus Studentized residuals. The residual plot of y hat versus Studentized residuals
(Fig 8a) seems appropriate because the residuals fall within a horizontal band centered around
0.
Fig 8a
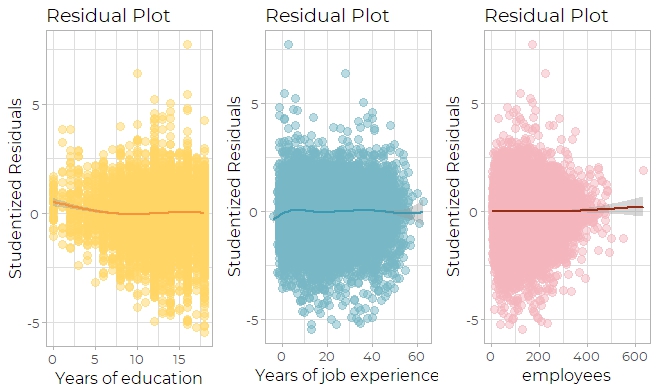
By inspecting the three scatter plots of explanatory variables versus Studentized residuals
(Fig 8b), it can be seen that the shape of residuals are in good shape: centered around 0 in a
horizontal fashion.
Fig 8b
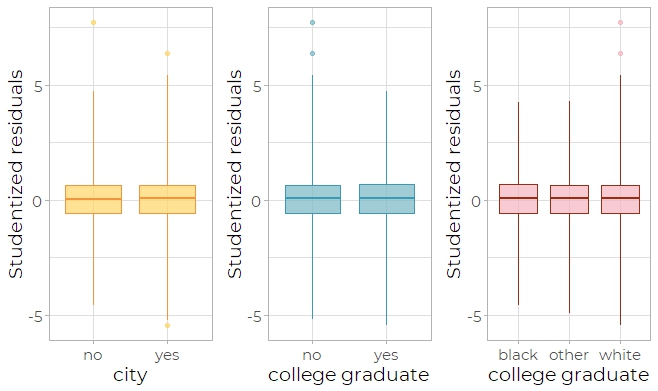
The third diagnostic plot is the box plot (Fig 9), which plots the categorical variables
versus the Studentized residuals. Only a few outliers exist, which means this model is
appropriate in normality.
Fig 9
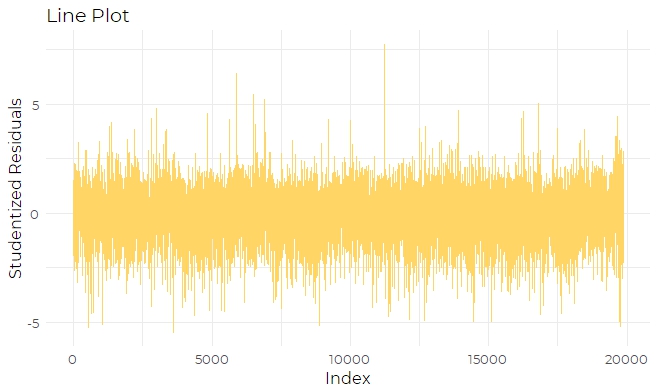
The final diagnostic plot is the line plot (Fig 10), which detects whether there are
dependent errors in the model. The line plot does not exhibit any pattern, so it indicates
that this model has independent errors, which is appropriate.
Fig 10
The MSE of the final model is 0.26, and the computed MSPR is 0.263, which is fairly close
to MSE, a good indication of the predictive ability of the model.
presents an analysis for the recent 5 years data of 10 companies, Apple, Amazon, Bank of America, Facebook, Google, IBM, JP Morgan, Microsoft, Target and Wal...